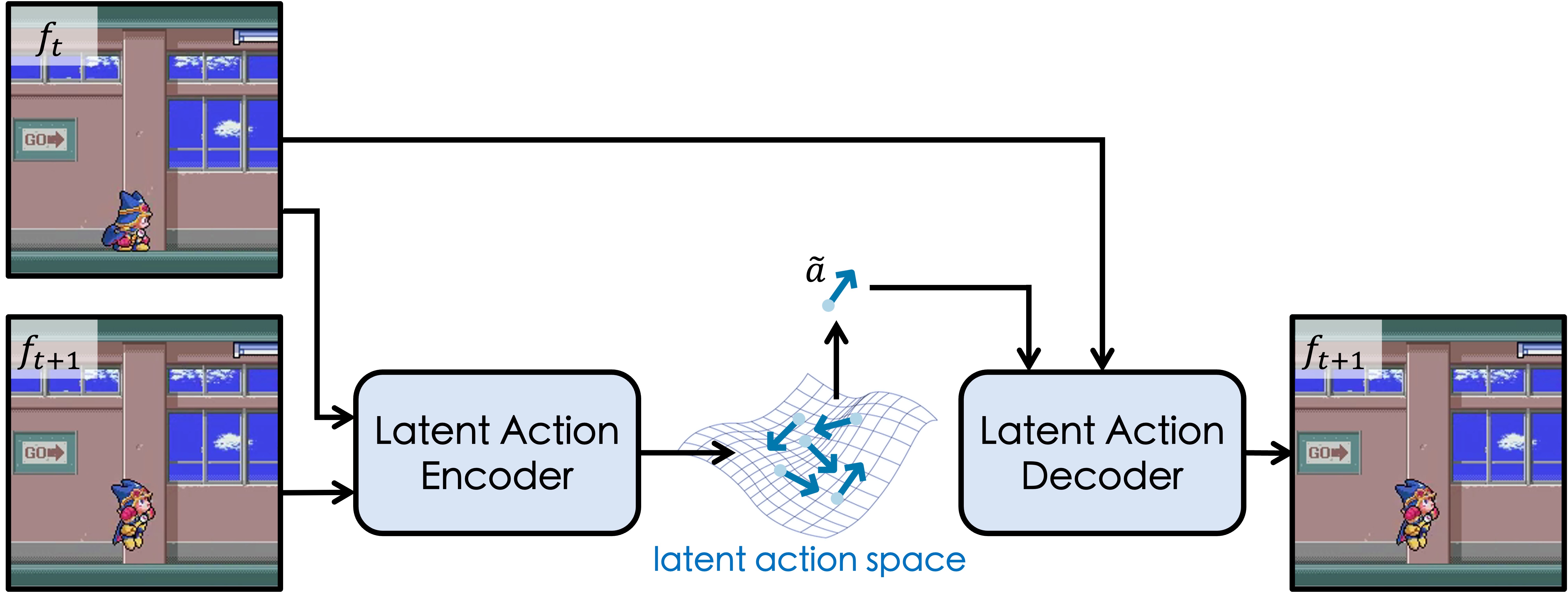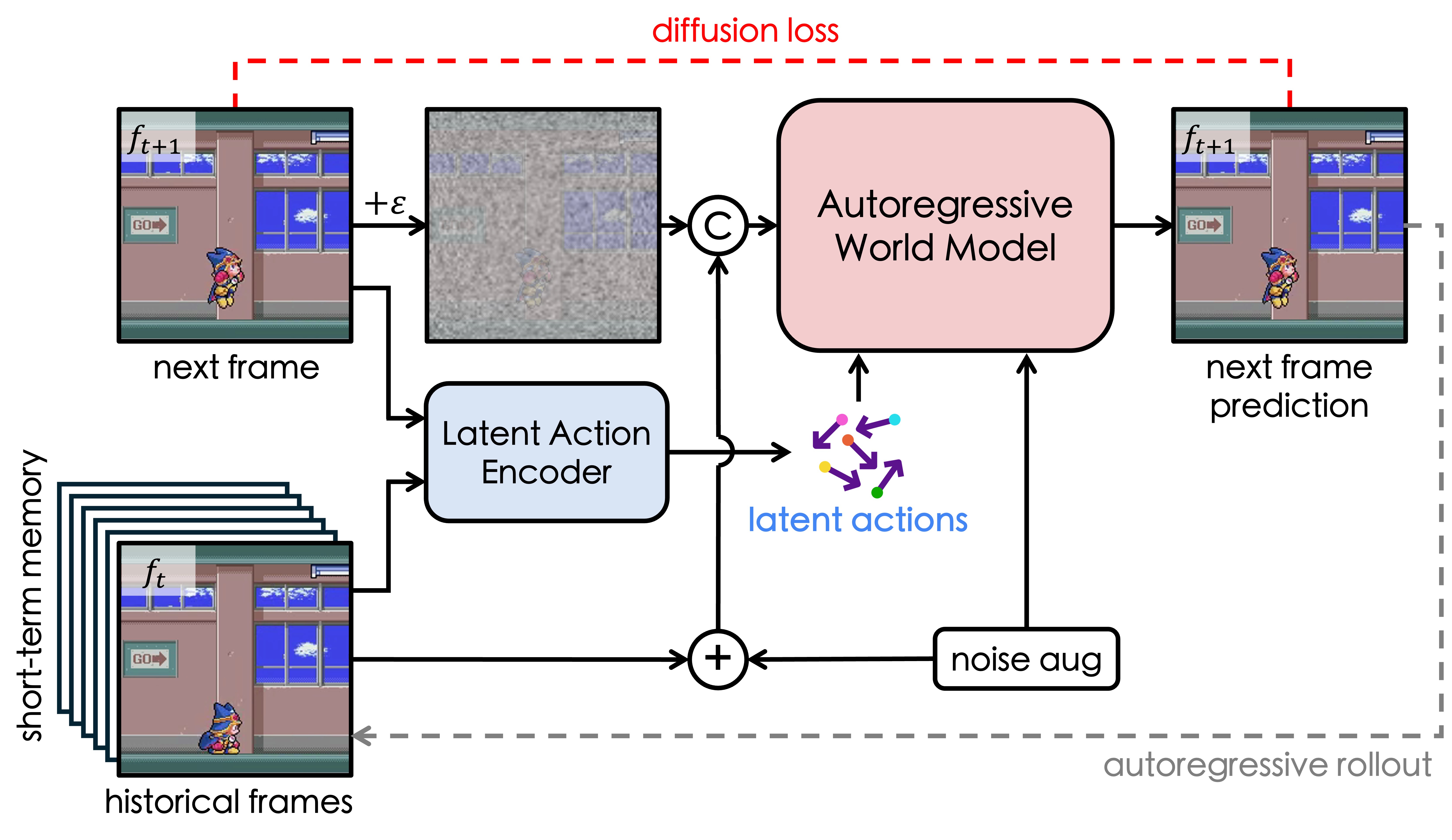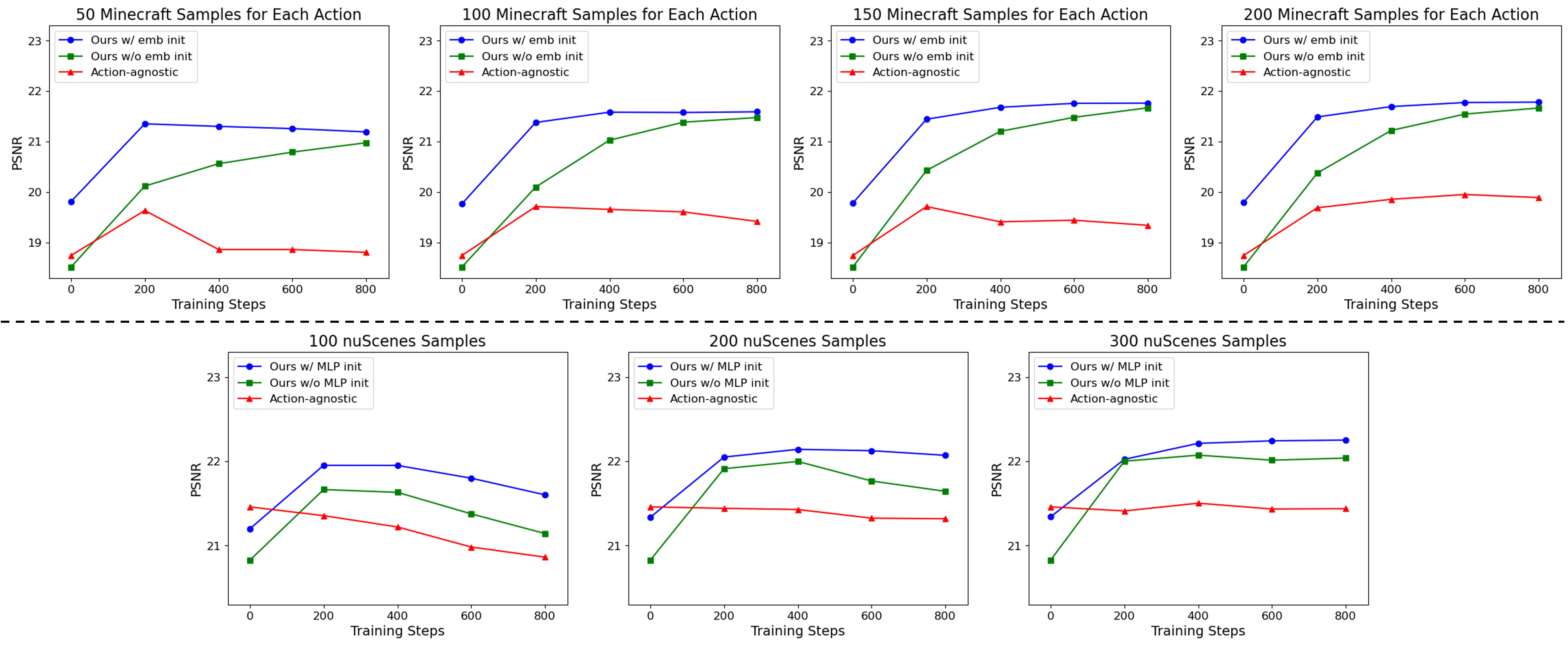
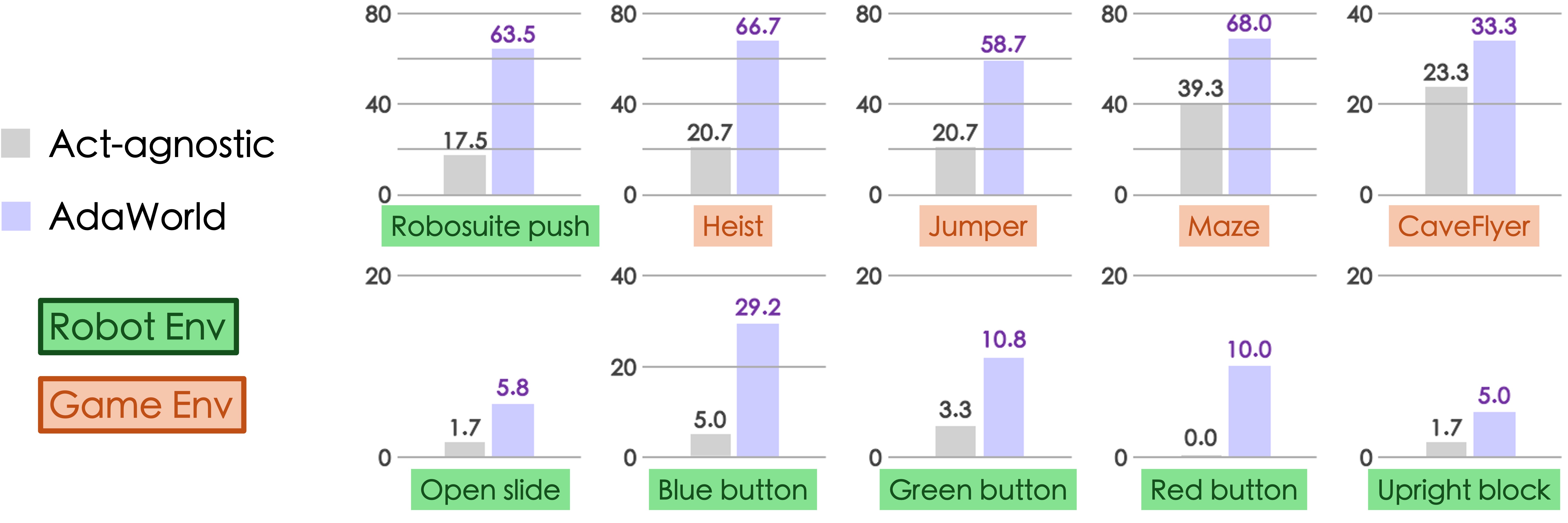




@inproceedings{gao2025adaworld,
title={AdaWorld: Learning Adaptable World Models with Latent Actions},
author={Gao, Shenyuan and Zhou, Siyuan and Du, Yilun and Zhang, Jun and Gan, Chuang},
booktitle={International Conference on Machine Learning (ICML)},
year={2025}
}